This morning I didn't have a lot going on, and I decided to upgrade my laptop from Posgres 9.3.4 to 9.4.1 as there are a few little things in 9.4 that are nice, and I've got 9.4 on my work laptop, and I figured this would be an easy upgrade - like super easy... I was mistaken.
The rules about automatic upgrades for Postgres is a bug release version change. I thought it was a minor release. So I was expecting to simply shut down the server, upgrade the packages with Homebrew, and then start it back up. The code would detect that it was the next minor version, and automatically update the data. Sadly, that's not the case. It's a big upgrade, and that means that I might as well do a complete dump/load.
Sadly, I didn't do a dump, so I'd have to live with an older version. Not a tragedy, but annoying when I'm in the middle of the upgrade process only to learn that it's not going to work. So it goes...
So here's what I had to do - in the right order to get things working. Not bad, but it's basically the instructions for a dump/load, so I'll assume we know this going in.
First, create a complete dump of the database. Assuming that all these things are installed on Mac OS X, and using Homebrew, the paths are not important - they are all fixed with Homebrew, anyway.
$ pg_dumpall > dump_file
Next, shut down the running server, update Homebrew, and then upgrade postgres within Homebrew. Just to be safe, let's re-link the launchctl file because in this case, it has changed, and better safe than sorry.
At this point I need to move the old database data to the side, and then initialize the database with the new codebase. Once that's done, we can then restart it with the re-linked launchctl file.
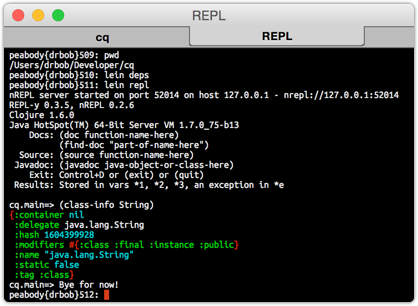
I was working on stripping out a little bit of code from a project at The Shop today, and when I stripped out the library I had made, I got the following error when trying to start the REPL:
$ lein repl
Exception in thread "main" java.lang.NoClassDefFoundError:
clojure/tools/logging/impl/LoggerFactory, compiling:
(/private/var/folders/ct/jhkds06j26v1lq2t40jx4cndl_629q/T/
form-init4416651774354867948.clj:1:124)
at clojure.lang.Compiler.load(Compiler.java:7142)
at clojure.lang.Compiler.loadFile(Compiler.java:7086)
at clojure.main$load_script.invoke(main.clj:274)
at clojure.main$init_opt.invoke(main.clj:279)
at clojure.main$initialize.invoke(main.clj:307)
at clojure.main$null_opt.invoke(main.clj:342)
at clojure.main$main.doInvoke(main.clj:420)
And if I put the library in the project.clj, I don't get this error, but if I take it out, I get this error. And I needed to take it out.
When I did a lien reps :tree to see what overlaps there might be in the libraries, I found a few in the Google AdWords libraries. Easily enough, I took them out, and forced the right version with a simple:
because the conflict was in the Google jars and both 2.5 and 2.6 of commons-lang were being used. Simply exclude them both, reference 2.6 first, and that should take care of it.
But it didn't.
So I took to the Google and found that someone had solved this by putting the class in the :apt section of the project.clj file. So with that, I tried:
:aot[clojure.tools.logging.impl bartender.main]
and then things started working just fine again.
I'm guessing that by building the uberjar for the other library, it did this compilation, so that it wasn't necessary for this project. Take it out, and we have a problem. Force the compile first, and it's all good.
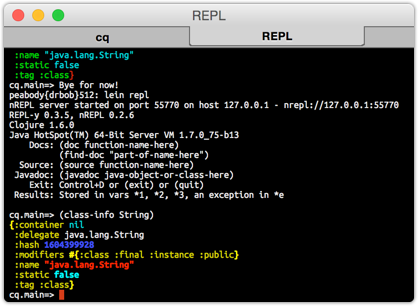
Today has been a day for colorization, and while I was at it, I decided to see what I could find that did this for Leiningen's REPL. What I found was simply too cool to believe.
There'a a GitHub project called Ultra - and it's a plugin for Leiningen that colorized the return values from the REPL so that they are a lot easier to read. Keywords, strings, numbers, maps... all are a lot easier to read with this plugin. And installing it was easy.
First, I needed to update to the latest Leiningen - and since I'm using the one in Homebrew, that's just:
$ brew upgrade leiningen
and let it finish. This brought me to version 2.5.1.
Now just add to my ~/.lein/profiles.clj the user section:
All the dependencies will be downloaded, and then you'll see something really cool like:
And this is going to make it all so much easier to work in the REPL. I remember going from a black-and-white editor to a colorized editor and it was as if the world of coding had changed. No longer did I have to stare intently at the code to discern it's meaning, the color told me what was important, and what wasn't. It was just amazing to my productivity.
I'm hoping I get even a fraction of that boost using these new colorization tools for log4j files and the REPL. How exciting!
UPDATE: I played around with the colors to make it look a little more like the clojure syntax file for Vim:
where the new ~/.lein/profiles.clj file looks like:
I'm not completely happy with these colors, but they are about as good as I'm likely to get with the ANSI color selections at my disposal. And hey... let's not forget... it could be a lot worse! 🙂
[11/20/2018] UPDATE: I've gone back and updated to the latest version of the plugin, and updated the colors for something that's much more interesting to me. The plugin is now specified as:
which includes the new colors for the symbol, number, class name, and exception. I was never a fan of the bold blue for numbers, because on a dark background, it was way too hard to read. Now it's just great. Much improved.
This morning I had to really smile... and even do my Happy Dance in my chair. I used something I found in the clojure library adworj to make reporting on Facebook ad server data as nice and clean as the code I lifted from adworj. I really liked adworj, but he wanted to handle credentials one way, and I had to have them in a separate store, so there were enough differences that the only really good things were the metadata on the reports from AdWords.
So what I decided to start with was a slight variant on the report metadata that he used. I started with a similar metadata structure, but instead of the macros and defrecord, I chose a simpler map of the data:
(def reportstats-fields
"The complete list of all allowed fields in the Facebook ReportStats
reporting system keyed on the nice clojure name, and including the
Facebook name and an optional parser for the returned data."{:time-start {:name"time_start" :parse parse-long}
:time-stop {:name"time_stop" :parse parse-long}
:date-start {:name"date_start" :parse to-date-time}
:date-stop {:name"date_stop" :parse to-date-time}
:account-currency "account_currency"
:account-id {:name"account_id" :parse parse-long}
:account-name "account_name"
:adgroup-id {:name"adgroup_id" :parse parse-long}
:adgroup-name "adgroup_name"})
where I've clearly truncated the list of fields from Facebook, but you get the idea. There is either a string that's the Facebook field name, or there's a map with two keys: :name for the Facebook name of the field, and :parse for the function to mars the value into it's clojure data element.
My real divergence starts with how the reverse-mapping is done. I start by having a defined set of all the field names, as opposed to computing it on the fly over and over again:
(def all-fields
"Set of all valid keyword/field names for the Facebook ReportStats
reports."(set(keys reportstats-fields)))
and then another that defines a map for how to get a Facebook field into closure-land:
(def coercions
"Map of the Facebook field names to the `:parse` functions for those
fields - if they exist in the report definition. If they don't, then
don't map anything and they won't then be handled in the
reading/parsing."(into{}(for[[n md] reportstats-fields
:let[nf (if(string? md) md (:name md))
cf (if(string? md) identity (:parse md))]][(keyword nf)(fn[v][n (cf v)])])))
What I like about this approach is that we don't have to deal with the overhead of doing this for each report each time it's run. While that's probably not a big overhead, why? Why spend any time on this once it's done? The report structures are fixed in both cases, and there's just no reason for that level of flexibility.
What the coercions map gives me is a collection of functions to map the values coming back from Facebook - keyed by their Facebook field name, and suitable for inclusion into a map - with the correct clojure keyword for the field name. For instance:
(defn coerce-record
"Function to take a record from Facebook, and apply the known mappings
to get it **back** into decent clojure names and datatypes."[m](into{}(for[[k v] m]((get coercions k) v))))
This function simply creates the right map (record) from the Facebook map (record) in a very simple, easy way. If there's a change in the formatting, just change the structure and it'll automatically be fixed in subsequent calls. That's nice.
Need to have a new field? Add it. Or change the name... it's all so easy to report like this.
Best of all, the real reporting code is just a vector of keywords to define what to get, and then a simple all. Very nice indeed!
Posted in Clojure Coding, Cube Life | Comments Off on Clojure Makes a Great Reporting Framework
One thing that I didn't yet have a handle on with LightTable is how to get this to act as my REPL - for an existing project. Simple one-file projects, or tests were easy, but I wanted to have a REPL that was also an editor - and I was clueless how to get that working.
So I decided to dig in and figure it out.
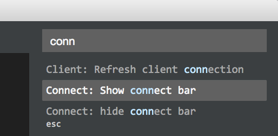
Turns out, it's really pretty easy. First, you have to start up LightTable, and then open up the command list and search for 'connect'. What you're going to do is to create a new connection. So find the 'connect bar':
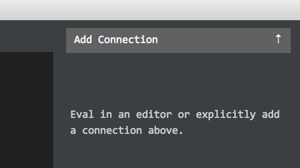
then click on 'Add Connection':
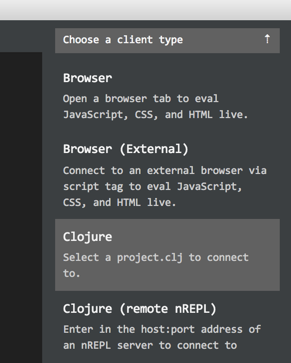
and then select the 'Clojure' item:
and then select the project.clj file and you're in business!
Simply open up an InstaREPL, and you're in a REPL in that project. Very nice!
One of the things that I've really missed in the latest version of Mac OS X is the utility to set the default version of the JDK to use. Well, with all the clojure coding I've been doing, I have typically stuck to JDK 1.7, but recently, the auto-updater from Oracle has them shipping JDK 1.8. Yet this doesn't effect the command-line utilities. This is a pain in the neck.
So first, I got JDK 1.7.0_75 on all my machines - it's going to be the last version of JDK 1.7 that I'll get as it's off the auto-updater. Then I was sure that everything was OK, I also got the complete JDK 1.8.0_40 - which is what the auto-updater downloaded for the JRE, but not the JDK. Yes, annoying.
At that point, I started googling about what to do. Turns out, JAVA_HOME is all I need to worry about. The java, jar, java apps in /usr/bin are all respectful of JAVA_HOME. Then I found this function that I added to my ~/.bashrc:
## Clever trick to leverage the /usr/bin/java commands to take advantage# of the JAVA_HOME environment variable and the /usr/libexec/java_home# executable to change the JDK on-the-fly. This is so easy I'm amazed.#function removeFromPath(){exportPATH=$(echo$PATH|sed-E-e"s;:$1;;"-e"s;$1:?;;")}function setjdk(){if[$#-ne0]; then
removeFromPath '/System/Library/Frameworks/JavaVM.framework/Home/bin'if[-n"${JAVA_HOME+x}"]; then
removeFromPath $JAVA_HOMEfiexportJAVA_HOME=`/usr/libexec/java_home -v $@`# export PATH=$JAVA_HOME/bin:$PATHfi}
setjdk 1.7
At this point, I saw that the key command was /usr/libexec/java_home, and it had all the answeres I needed. I didn't need to update my PATH - just JAVA_HOME. I also could verify that I had all the versions of Java I needed:
$ /usr/libexec/java_home -V
Matching Java Virtual Machines (7):
1.8.0_40, x86_64: "Java SE 8"/Library/Java/JavaVirtualMachines/jdk1.8.0_40.jdk/
Contents/Home
1.7.0_75, x86_64: "Java SE 7"/Library/Java/JavaVirtualMachines/jdk1.7.0_75.jdk/
Contents/Home
1.7.0_51, x86_64: "Java SE 7"/Library/Java/JavaVirtualMachines/jdk1.7.0_51.jdk/
Contents/Home
1.7.0_45, x86_64: "Java SE 7"/Library/Java/JavaVirtualMachines/jdk1.7.0_45.jdk/
Contents/Home
1.7.0_13, x86_64: "Java SE 7"/Library/Java/JavaVirtualMachines/jdk1.7.0_13.jdk/
Contents/Home
1.6.0_65-b14-466.1, x86_64: "Java SE 6"/System/Library/Java/JavaVirtualMachines/
1.6.0.jdk/Contents/Home
1.6.0_65-b14-466.1, i386: "Java SE 6"/System/Library/Java/JavaVirtualMachines/
1.6.0.jdk/Contents/Home
And then with a simple command - in the shell of my choice - I can set - and reset the JDK I use. It's very click:
I've got a few projects on Bitbucket, and while it's nice to have an alternative to GitHub's policy on private repos, the Markdown rendering on Bitbucket is really sad. The problem is simple: If I have a repo with images in it, and I want to include them in the README.md, then for GitHub I need to include something like:
and it'll work - but including the HTML, as per the Markdown standard, on Bitbucket is not allowed. They have written that they don't allow any HTML in their Markdown due to safety reasons. But then why does GitHub? Is it just because Bitbucket isn't using as good a parser?
In addition to the lack of HTML, the relative links in the Markdown aren't supported, either. This means that in order to include an image in the README.md, I have to do something like:

this means that the links don't work in local preview mode, and a lot of folks have been asking for more than a year, to have this fixed. Their answers have ranged from "It's a feature", to "It's on the list, with no ETA". Clearly, the company isn't listening to it's users. That's sad.
For Bitbucket, the issue seems to be revenue. They don't seem to feel the need to fix this serious documentation issue, and it can't be all that hard if GitHub has had it from the beginning. The people on the ticket have even quoted (and linked) the Markdown spec as well as how GitHub is doing this - and nothing has changed.
I can appreciate that this is their choice. Mine is to use it only if I have to, and realize that their idea of support is "No, thanks", and accept what is, over any hopes of what might be.
I'm not a fan of OAuth2... not in the least. It's excessively complicated, it requires call-backs, and in general it's no more secure than anything else, it's just more complicated. Add to that there's no really good library for it as the Google folks keep changing things, and you have something that's always going to require hacks... always going to require fixing, and never going go provide a seamless way to authenticate on a remote system.
But that's just an opinion. I have had to make it work at The Shop, and when I finally got it to work, I wasn't about to let this evaporate into the ether... I needed to make a gist of it, and document what I was doing so that I could come back to this and be able to remember it all at a later date.
The State of OAuth2 Clojure Libraries
The first really depressing thing was that there seemed to be no decent OAuth2 libraries for Clojure. And while there seemed to be a lot of forks of the clj-oauth2 library - but many, like the original, were years old - and they didn't work. Not even close. Now I'm not silly enough to think that the spec changed, but I do believe that Google changed things on it's end to make it more secure, and in so doing, broke all the clj-oauth2 work, and it's derivatives.
Still, there is the code I can look at. And some have pulled in the features that are needed, and so it's not impossible to make this thing work... though it's likely to take a lot of time.
The project.clj File
When I was able to get something working, I made a gist of all the important files, so that I could include them here as reference. I also wanted to post the link to the #clojure room in IRC because one of the guys there gave me a hint as to which library to use. He wasn't right, but he was close, and that's all I needed.
The project.clj file has all the versions of the libraries I used:
What I found was that this version of clj-oauth2 had the most complete mapping of the data coming from Google, which included the expires-in time - which I think I still may be able to put to really good use soon. While it didn't have the functions to renew the access-token, it turns out that it's not hard to write, and I pulled that from another fork of the master project.
The server.clj File
OAuth2 still requires that the user go to Google on a redirect, and then the call-back from them is where we get the first bit of the authentication data. I'm not convinced that this is at all necessary, but it's how things are. Given that, we needed to have the server.clj have an endpoint /google that gets redirected to the right place at Google for the user to login and accept the app.
There is also the callback endpoint, and then a few that return the token data, and renew the token. Nothing special, really, but the targets for the OAuth2 are really important, and it's just sad that we have to have them in the first place.
The dcm.clj File
The final piece is really the meat of the problem.
We start off with the Missing Functions in the clj-oauth2 library, and then jump right into the static config for our application. These are all generated by Google, and you can get them from Google when you register your project/client.
We then have the authentication and re-authentication functions, which took an enormous amount of time to get right, but don't look overly complex in the least. Lovely.
Finally, we have a few calls to test that we got the user profile information properly, and that we can make subsequent calls to Google and get the data requested. It's not a lot, but it works, and it proves that things are working up to that point.
In the end, I'm glad I have it all done, and I'll be integrating the Custos Server in as a secret store of the credentials soon. Then I'll be using redis as the back-end and then pulling data from Google and loading it there. All this is a complete, stand-alone, back-end data collector for the ad messaging data for a client from Google.
I've been doing a little work on the Clojure CryptoQuip solver by adding a new RESTful endpoint for the server that takes the quip and the clue and solves the puzzle. It's not all that hard, but it's a POST call, as the body of the POST is JSON, and I needed a tool to hit my server to make sure that I had it all working. Enter Postman.
This is just an amazing tool for Chrome. It's a very singular task, and it does an excellent job of making sure that you can make all the calls you need with all the headers and arguments and get back what you need - and even keep a running history of all the calls to re-do should you need them.
Clearly the folks that wrote this knew what they needed and spent quite a bit of time on it. I have yet to find a hole, a bug, or a limitation. It's just good, solid working code. And it's free. Wow. Impressive.
I looked at several of the OS X tools on the App Store, and even on the web and the nice ones were more than $20, and most weren't nearly as nice as Postman. If you need something like this, you need it, and this is as good a tool for the job as you can get.
Today I was talking with Carl, the friend I was doing a little side-project with in Clojure, and it was pretty clear that he didn't understand what the next steps were for the project, and while I tried to explain it to him, he's thinking in terms of cross-sectional probability functions, and I'm thinking this is all a massive Monte Carlo simulation system where the PDFs for the individual events are what you tweak, and then you run the simulation for a year of time, and see what happens. It's very simple, and while it doesn't give you direct control over the things out might want to control, it does give you the ability to see how individual actions - the promotions from one step in the sales pipeline to the next, impacts revenue.
Anyway, so I wanted to make sure that it was all running nicely, and I was using Gorilla REPL for the REPL as it has nice graphing as well as being a generally good REPL, but as I was making changes to the code and refreshing the page, I wasn't seeing what I expected to see.
Then it hit me - Gorilla REPL wasn't reloading the code.
Ouch.
I then switched to using the standard REPL with Leiningen, and everything worked fine - then firing up Gorilla REPL and reloading the page showed that it was now working just fine. Lesson learned - Gorilla doesn't reload the code when you re-execute all the code.
Posted in Clojure Coding, Coding | Comments Off on Did a Sales Simulation Phase – Reloading in Gorilla REPL