Struggling with Storm and Garbage Collection

OK, this has to be one of the hardest topologies to balance I've had. Yeah, it's only been a few days, but Holy Cow! this is a nasty one. The problem was that it was seemingly impossible to find a smoking gun for the jumps in the Capacity of the bolts for the topology. Nothing in the logs. Nothing to be found on any of the boxes.
It has been a pain for several days, and I was really starting to get frustrated with this guy. And then I started to think more about the data I had already collected, and where that data - measured over and over again, was really leading me. I have come to the conclusion it's all about Garbage Collection.
The final tip has been the emitted counts from the bolts during these problems:
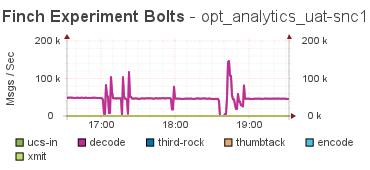
where the corresponding capacity graph looks like:
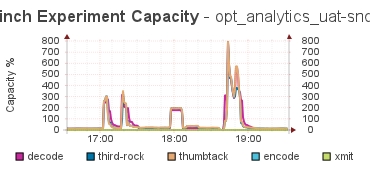
The tip was that there was a drop in the emitted tuples, and then a quick spike up, and then back to the pre-incident levels. This tells me that something caused the flow of tuples to nearly stop, and then the system caught back up again, and the integral over that interval was the same as the average flow.
What lead me to this discovery is that all the spikes in the Capacity graph were 10 min long. Always. That was too regular to be an event, and as I dug into the code for Storm, it was clear it was using a 10 min average for the Capacity calculation, and that explains the duration - it took 10 mins for the event to be wiped from the memory of the calculation, and for things to return to normal.
Given that, I wasn't looking for a long-term situation - I was looking for an event, and with that, I was able to start looking at other data sources for something that would be an impulse event that would have a 10 min duration effect on the capacity.
While I'm not 100% positive - yet - I am pretty sure that this is the culprit, so I've taken steps to spread out the load of the bolts in the topology to give the overall topology more memory, and less work per worker. This should have a two-fold effect on the Garbage Collection, and I'm hoping it'll stay under control.
Only time will tell...
UPDATE: HA! it's not the Garbage Collection - it's the redis box! It appears that the redis servers have hit the limit on the forking and writing to disk, and even the redis start-up log says that there should be the system setting:
vm.overcommit_memory = 1
to /etc/sysctl.conf and then reboot or run the command:
sysctl vm.overcommit_memory=1
for this to take effect immediately. I did both on all the redis boxes. I'm thinking this is the problem after all.
Best results I could have hoped for:
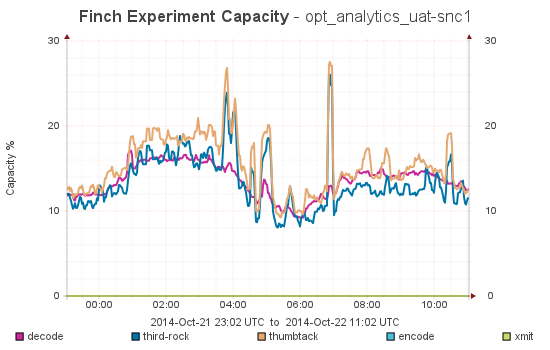
Everything is looking much better!